人工智能研究 從基礎理論到軟件開發的核心知識體系

從事人工智能(AI)研究,特別是在基礎軟件開發領域,需要構建一個跨學科、多層次的知識體系。這不僅包括對核心算法的深刻理解,還涉及扎實的工程實踐能力和對應用場景的洞察。以下是為有志于投身此領域的研究者梳理的關鍵知識范疇。
一、數學與統計基礎:AI的通用語言
這是構建一切AI模型的基石,不可或缺。
- 線性代數:理解向量、矩陣、張量及其運算,是掌握神經網絡(尤其是深度學習)前向傳播、反向傳播的必備工具。
- 概率論與統計學:為機器學習中的貝葉斯理論、概率圖模型、不確定性問題建模以及評估指標(如置信區間、假設檢驗)提供理論支撐。
- 微積分與優化理論:梯度下降及其變種(如Adam、SGD)是訓練模型的核心,需要理解導數、偏導數、鏈式法則以及凸優化等概念。
- 信息論:在特征選擇、模型壓縮和某些學習算法(如決策樹)中起到重要作用。
二、計算機科學核心:實現能力的保障
AI研究最終要通過代碼和系統來實現。
- 編程語言:
- Python:當前AI領域的主流語言,擁有豐富的庫生態(如NumPy, Pandas, Scikit-learn, PyTorch, TensorFlow)。必須精通。
- C++:對于追求高性能、低延遲的底層框架開發、模型部署或邊緣計算至關重要。
- 數據結構與算法:高效的數據組織(如圖、樹)和經典算法(如搜索、排序)是優化AI系統性能的基礎。
- 操作系統與計算機體系結構:理解內存管理、多線程/多進程、GPU并行計算(CUDA)等,能幫助開發出更高效、穩定的AI軟件。
- 軟件工程:包括代碼版本控制(Git)、模塊化設計、測試、調試以及協作開發規范,是進行大型、可持續AI項目開發的必備技能。
三、人工智能與機器學習核心理論:領域的專業知識
這是區別于普通軟件開發者的核心。
- 經典機器學習:必須掌握監督學習(線性回歸、邏輯回歸、SVM)、無監督學習(聚類、降維)、強化學習的基本原理與算法。
- 深度學習:深入理解神經網絡的各種架構,如卷積神經網絡(CNN)、循環神經網絡(RNN)及其變體(LSTM, GRU)、Transformer,以及注意力機制、生成模型(GAN, VAE, 擴散模型)等。
- 領域前沿:跟蹤如大語言模型(LLM)、多模態學習、可解釋性AI、聯邦學習、神經符號計算等前沿方向。
四、人工智能基礎軟件開發專項技能
這是將理論轉化為強大工具的關鍵環節。
- 框架深度使用與原理:不僅要會用PyTorch/TensorFlow/JAX等框架,更要理解其自動微分、計算圖構建、分布式訓練等核心機制。
- 模型訓練與優化:精通大規模數據處理、分布式訓練策略、混合精度訓練、超參數調優、模型收斂性分析與調試。
- 模型部署與工程化:掌握模型壓縮(剪枝、量化)、轉換(ONNX)、以及在不同環境(服務器、移動端、瀏覽器)的部署工具(如TensorRT, OpenVINO, TensorFlow Serving, Triton Inference Server)。
- 系統設計能力:能夠設計高可用、可擴展的AI服務平臺,考慮模型版本管理、A/B測試、監控、持續集成/持續部署(CI/CD)流水線。
五、領域知識與軟技能
- 特定應用領域知識:如從事計算機視覺需了解圖像處理;從事自然語言處理需了解語言學基礎。這能幫助定義更有價值的問題和設計更合理的模型。
- 研究能力:包括文獻檢索與閱讀(ArXiv, 頂會論文)、提出創新想法、設計實驗、撰寫學術論文或技術報告的能力。
- 問題解決與批判性思維:AI研究充滿未知,需要具備將復雜問題分解、提出假設并通過實驗驗證的能力。
學習路徑建議
學習路徑并非線性,建議采取“理論-實踐-迭代”的循環方式:
- 筑牢基礎:從數學和編程開始,同步學習經典機器學習課程(如吳恩達或李宏毅的課程)。
- 深入實踐:選擇一個主流深度學習框架,通過復現經典論文、參加Kaggle比賽或完成實際項目來鞏固知識。
- 參與開源:閱讀和貢獻優秀的AI開源項目(如Hugging Face Transformers, PyTorch Lightning),是學習工程最佳實踐的捷徑。
- 專注前沿:在掌握核心后,選擇一個細分方向(如大模型推理優化、科學智能)進行深入研究。
人工智能研究和基礎軟件開發是一個對綜合能力要求極高的領域。它要求從業者既是能洞悉數學原理的理論家,也是能構建穩健系統的工程師,同時還是能不斷探索未知的研究者。保持持續學習的熱忱和對技術細節的執著,是在這個快速演進領域立足的根本。
最新產品
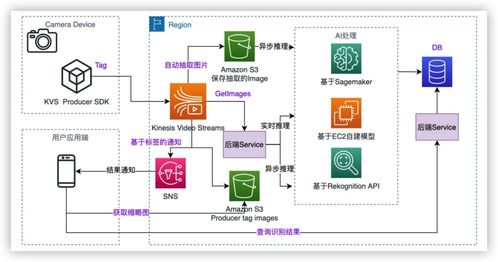
科技沙龍回顧 基于Amazon KVS構建智能視覺產品的實踐與洞見
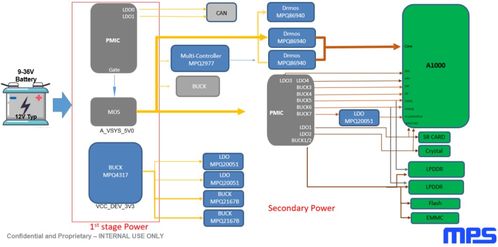
MPS車規級多相電源 為黑芝麻智能ADAS明星產品與人工智能基礎軟件開發保駕護航
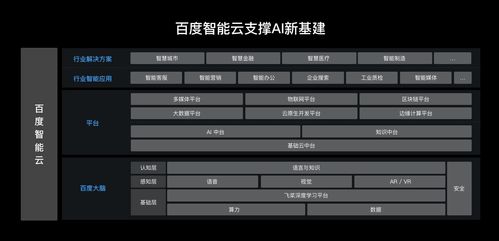
人工智能技術開發人員應遵循的7條道德準則

人工智能芯片發展的10大盤點與10大預測 從硬件基石到軟件生態的協同演進
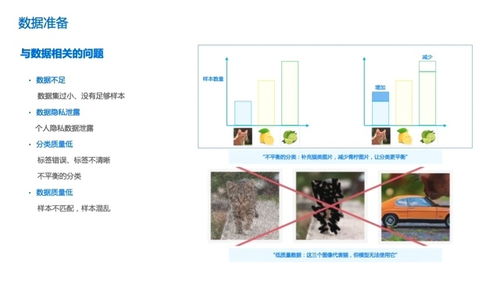
人工智能項目開發與規劃 基礎軟件開發的基石與藍圖
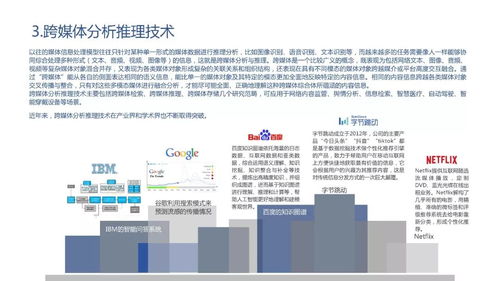
人工智能浪潮奔涌 基礎軟件開發展現實力,中國力量躋身全球前列
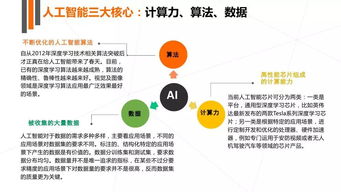
2017年人工智能基礎軟件開發行業研究報告
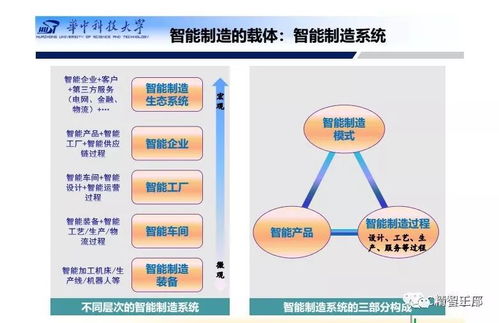
智能工廠總體規劃與建設 基于人工智能基礎軟件的深度解析
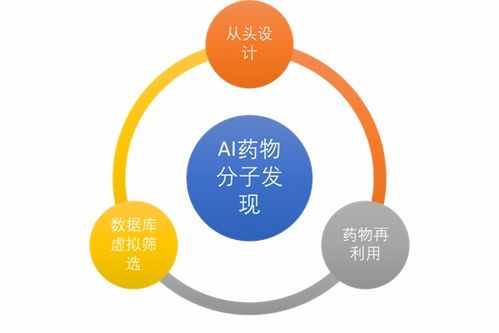
人工智能如何賦能小分子藥物開發 基礎軟件的關鍵角色
從信息化到智能工廠 如何以人工智能基礎軟件開發搭建數字化轉型的關鍵橋梁